SEPID Corpus: Segmented, Pre-Processed, Indexed ACL ARC 1.0
Skip descriptions and go to
- Download SEPID_CORPUS Index Files;
- Download Redundant Index Files;
- Download SEPID CORPUS Index Files Grouped by Publication Year;
- Download and Explore Truncated Examples Files.
SEPID CORPUS is the segmented processed ACL ARC documents that are represented in a data model as shown in the figures shown below. In this representation, each linguistically well defined unit, i.e. lexemes (part-of-speech-tagged, lemmatized words), sentences, paragraphs, sections, etc., is identified by a unique identifier. Moreover, units of higher granularity than lexemes consists of a combination of linguistic units of a finer level of granularity. For instance, a sentences consists of a list of lexemes and their position in the sentence; paragraphs are lists of sentences and so on. These representation of text is then serialized using a set of tab-separated text files; each text file represent a particular linguistic unit (data-entity in the given diagrams).
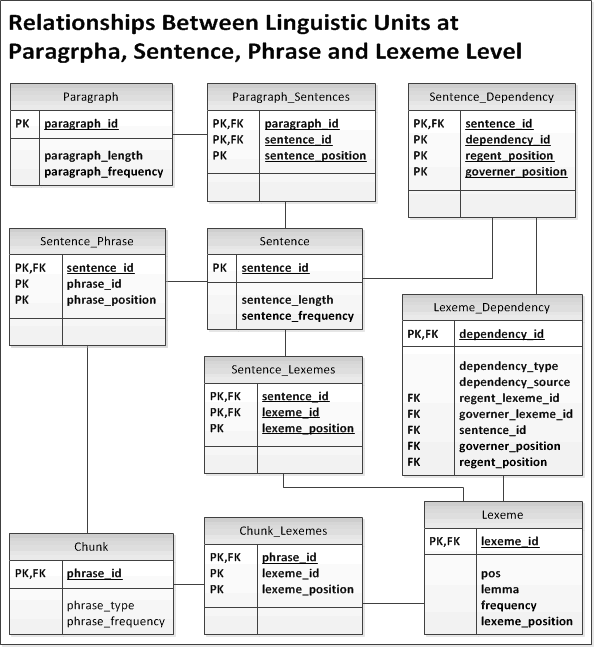
Text data-entity relationships diagram at levels finer than paragraph
In order to model nested sections and subsections, text units of a granularity level higher than paragraphs are all consider as a content-unit of specific content-type. Each of these units is then a list of content-unit and at a specific position. Further information about the content_unit can be found in the relevant file to that text unit.
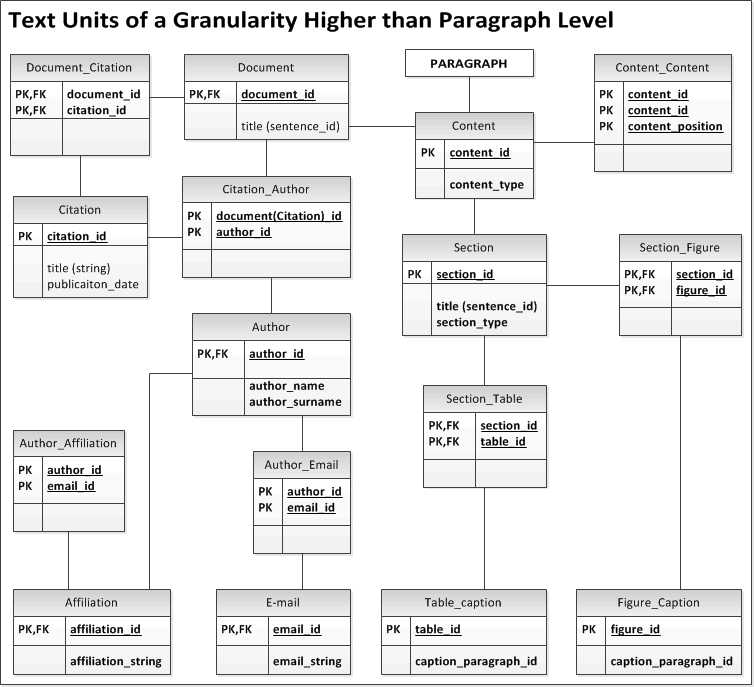
Text data-entity relationships diagram at levels higher than paragraph
The presented data in the listed files here are derived from processing the cleansed text documents using the Stanford tokenizer and part-of-speech tagger (version release date 9 July 2012), the Apache OpenNLP's sentence splitter and Chunker(version 1.5) and MaltParser(version 1.6), a data-driven dependency parser.
Each of the data-entities in the above figures are represented by a tab-separated text file. The first line of each file starts with character "#" and describe the content of records in the file. The corpus files can be downloaded from the list given below:
SEPID CORPUS |
|||
| Size: | Name: | Description: | |
| 554.505.209 | sepid_corpus.zip | All the files listed below in one zip file. | |
| 7.543.215 | _all_lexicon.zip | All the extracted lexemes, i.e. part-of-speech tagged, lemmatized words, that are extracted from the ACL ARC. The structure of this tab-separated file is as follows:
| |
| 2.358.739 | _all_sentence.zip | All the extracted sentences from the ACL ARC. This file contains only one column, i.e. the list of employed integers as SENTENCE_ID. | |
| 139.071.858 | _all_sentence_lexeme.zip |
This file defines the extracted sentences from the corpus as a list of the tuples (lexeme_id, lexeme_position). The structure of this tab-delimited file is as follows:
| |
| 24.908.979 | _all_chunk.zip | All the extracted chunks (phrases) from the ACL ARC.
This tab-separated file has records in the form of:
| |
| 85.975.964 | _all_sentence_chunk.zip | This file maps the extracted chunks to extracted sentences.
This tab-separated file has records in the form of:
| |
| 54.683.904 | _all_dependency.zip | All the extracted syntactic relations (dependencies) between lexemes in the corpus.
The structure of the records in this tab-separated file is as follows:
| |
| 226.281.573 | _all_sentence_dependency_parse.zip | The extracted syntactic relations are mapped into sentences.
The structure of the records in this tab-separated file is as follows:
| |
| 5.330.203 | _all_paragraph_sentence.zip | This file identifies the extracted paragraphs from the corpus. Each paragraph is formed of a list of sentences are certain position, i.e. the list of tuples (sentence_id, sentence_position).
The structure of the records in this tab-separated file is as follows:
| |
| 439.649 | _all_section.zip | All the extracted sections from the corpus.
The structure of the records in this tab-separated file is as follows:
| |
| 1.026.572 | _all_content_type.zip | The list of all text units other than lexeme, sentence and paragraphs, i.e. sections, documents, figures, tables and equations. This file is used to recover the text and the structure of documents. The structure of the records in this tab-separated file is as follows:
| |
| 1.722.830 | _all_content_content.zip | This file is used to retrieve/recover the structure and text for sections and documents.
The structure of the records in this tab-separated file is as follows:
| |
| 47.260 | _all_document.zip | The list of documents from the ACL ARC that are processed and indexed successfully.
The structure of the records in this tab-separated file is as follows:
| |
| 106.842 | _all_equation_caption.zip | All the extracted equations from the ACL ARC's sections.
The structure of the records in this tab-separated file is as follows:
| |
| 60.542 | _all_figure_caption.zip | All the extracted figures from the ACL ARC. Please note the figure themselves nor their position are not stored.
The structure of the records in this tab-separated file is as follows:
| |
| 56.392 | _all_section_figure.zip | Mapping between figures and documents in the corpus;
The structure of the records in this tab-separated file is as follows:
| |
| 40.852 | _all_table_caption.zip | The extracted table captions from the corpus.
The structure of the records in this tab-separated file is as follows:
| |
| 37.576 | _all_section_table.zip | Mapping between tables and documents in the croups;
The structure of the records in this tab-separated file is as follows:
| |
| 41.977 | _id_map_to_acl_arc.zip | This file gives the mapping between the employed integer ids for documents in the SEPID_CORPUS to the original ACL ARC ids.
The structure of the records in this tab-separated file is as follows:
| |
| 98.043 | _all_affiliation.zip | Extracted affiliations from the ACL ARC corpus. This tab-separated file contains the following information:
| |
| 1.004.429 | _all_author.zip | The list of extracted authors from the ACL ARC. This tab-separated file contains the following information:
|
|
| 43.115 | _all_author_affiliation.zip | Extracted Affiliations for the authors appeared in the corpus. This tab-separated file has records in the form of:
|
|
| 62.079 | _all_email.zip | All the extracted email addresses from the ACL ARC. This tab-separated file has records in the form of:
| |
| 24.031 | _all_author_email.zip | Extracted email addresses from the ACL ARC are assigned to authors. This tab-separated file has records in the form of:
| |
| 2.759.385 | _all_citation.zip | The list of all extracted citations from the ACL ARC.
The structure of the records in this tab-separated file is as follows:
| |
| 558.776 | _all_citation_author.zip | The list of authors of the extracted citations.
The structure of the records in this tab-separated file is as follows:
| |
| 220.974 | _all_document_citation.zip | Indicate the list of citations for each document in the corpus.
The structure of the records in this tab-separated file is as follows:
| |
| <DIR> | sepid_corpus_examples/ | A short-truncated version of all the above listed files can be found in this folder. | |
| <DIR> | redundant_index/ | A Set of additional redundant indexes that may come handy, or make it easier to process the corpus, can be found in this folder. | |
| <DIR> | sepid_corpus_by_year_type/ | This folder contains the same data as the files listed above. However, each text file in this folder is broken into 34 different files, each file repents the text units that are extracted from articles published in a particular year, e.g. 67, 78, 92, and so on. | |
Directory contains 1.109.010.968 Bytes in 27 Files | |||
Redundant Index Files
A set of redundant index files that can help to manipulate, s/s/s/s/search and process the corpus are provided. The set of available files for download are listed below.
Index of: redundant_index/ |
|||
| <Up to the higher level directory> | |||
| Size: | Name: | Description: | |
| 136.001.881 | _redundant_index.zip | All the files listed below in one Zip file. | |
| 63.877.459 | _all_sentence_text.zip | All the extracted sentences from the corpus; each record is one line of the text file in which the field values in the record are separated by tab_character+<s>+tab_character. Each record has the following fields:
| |
| 59.163.252 | _all_paragraph_text.zip |
All the extracted paragraphs from the corpus; each record is one line of the text file in which the field values in the record are separated by tab_character+<p>+tab_character. Each record has the following fields:
| |
| 5.516.793 | _all_document_sentence.zip | Mapping between extracted sentences and documents.
The structure of the records in this tab-separated file is as follows:
| |
| 1.449.532 | _all_document_paragraph.zip |
Mapping between extracted paragraphs and documents.
The structure of the records in this tab-separated file is as follows:
| |
| 5.921.040 | _all_section_sentence.zip | Mapping between extracted sentences and sections. The structure of the records in this tab-separated file is as follows:
| |
| 73.579 | _all_orphan_sentence.zip | This file lists all the sentence ids that are not connected to any document. This problem is due to the incomplete indexing of some of the documents, e.g. because of a bug in codes, appearance of illegal characters in documents etc. This problem will be addressed in the release. The reocrds of this file are thus only SENTENCE_ID. | |
Directory contains 272.003.536 Bytes in 7 Files | |||
SEPID CORPUS Sectioned and Grouped by the Publication Year of Documents
Here you can download all the above listed text units in the SEPID CORPUS, however, when files are sectioned and organized by the year of publication of their origin documents. The structure of these files are exactly the same as the descriptions given in the table above.
Each of the files listed in the SEPID CORPUS (the above table) are broken down into 34 different files, each file represent the text units that are extracted from the documents published in a particular year. For example, the _all_lexicon file is broken down into 34 files, each file starts with a two digit number, e.g. 98, 87, 67 and so on, which shows the year of publication, followed by "_lexicon". In this way, the file 87_lexicon contains all the lexemes that are extracted from the documents published in the year 87 and the file "98_lexicon" contains all the extracted lexemes form documents published in year 98.
In the current release these 34 years are: '06', '05', '04', '03', '02', '01', '00', '99', '98', '97', '96', '95', '94', '93', '92', '91', '90', '89','88', '87', '86', '85', '84', '83', '82', '81', '80', '79', '78','75', '73','69', '67', '65' .
Index of: sepid_corpus_by_year_type/ |
|||
| <Up to the higher level directory> | |||
| Size: | Name: | Description: | |
| 623.815.172 | _sepid_corpus_by_year_type.zip | All the files listed below in one Zip file. | |
| 132.336 | affiliation.zip | Extracted affiliations, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 1.049.391 | author.zip | Extracted author names, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 53.147 | author_affiliation.zip | Extracted mappings between authors and affiliations, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 31.103 | author_email.zip | Extracted mappings between author names and email addresses, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 30.850.371 | chunk.zip | Extracted chunks, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 2.806.382 | citation.zip | Extracted citations, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 596.417 | citation_author.zip | Extracted mappings between authors and citations, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 1.960.407 | content_content.zip | Extracted content mappings, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 1.043.264 | content_type.zip | Extracted contents marked by their type, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 107.218.828 | dependency.zip | Extracted syntactic relations between words, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 59.717 | document.zip | Extracted documents, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 250.900 | document_citation.zip | Extracted document citations, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 85.957 | email.zip | Extracted email addresses, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 132.992 | equation_caption.zip | Extracted equations, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 77.716 | figure_caption.zip | Extracted figure captions, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 17.150.076 | lexicon.zip | Extracted lexemes (part-of-speech tagged, lemmatized words), grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 5.570.395 | paragraph_sentence.zip | Extracted mapping between paragraphs and sentences, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 458.957 | section.zip | Extracted text sections, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 68.211 | section_figure.zip | Extracted mappings between sections and figure captions, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 47.434 | section_table.zip | Extracted mappings between sections and tables, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 1.706.071 | sentence.zip | Extracted sentences, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 86.363.133 | sentence_chunk.zip | Extracted mappings between sentences and chunks, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 226.439.393 | sentence_dependency_parse.zip | Extracted mappings between syntactic dependencies and sentences, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 139.609.923 | sentence_lexeme.zip | Extracted mappings between sentences and lexemes, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
| 53.179 | table_caption.zip | Extracted table captions, grouped by the year of publication of their source documents. For the structure of the records see the description given above. | |
Directory contains 1.247.630.872 Bytes in 26 Files | |||
Example of Records in the SEPID CORPUS Index Files
You can explore the index files' structure in the truncated example files listed below.
Index of: sepid_corpus_examples/ |
|||
| <Up to the higher level directory> | |||
| Size: | Name: | Description: | |
| 27.501 | _affiliation | Example of Affiliation Index File | |
| 153.585 | _author | Example of Author Index File | |
| 9.369 | _author_affiliation | Example of Mapping Between Author and Affiliation Index Files | |
| 4.761 | _author_email | Example of Mapping Between Author and Email Index Files | |
| 395.388 | _chunk | Example of Chunk Index File | |
| 8.856 | _citation | Example of Citation Index File | |
| 2.421 | _citation_author | Example of Mapping Between Citation and Author Index Files | |
| 20.783 | _content_content | Example of Mapping Between Contents and Sub-Contents Index Files | |
| 22.735 | _content_type | Example of Content Index File | |
| 4.806 | _dependency | Example of Syntactic Dependency Index File | |
| 378 | _document | Example of Document Index File | |
| 1.451 | _document_citation | Example of Mapping Between Document and Citation Index Files | |
| 4.985 | _email | Example of Email Index File | |
| 1.401 | _equation_caption | Example of Equation Index File | |
| 1.564 | _figure_caption | Example of Figure Caption Index File | |
| 5.017 | _lexicon | Example of Lexeme Index File | |
| 3.463 | _paragraph_sentence | Example of Mapping Between Paragraphs and Sentences | |
| 2.243 | _section | Example of Section Index File | |
| 1.088 | _section_figure | Example of Mapping between Section and Figure Caption Index Files | |
| 1.492 | _section_table | Example of Mapping between Section and Table Caption Index Files | |
| 22.038 | _sentence | Example of Sentence Index File | |
| 3.589 | _sentence_chunk | Example of Mapping Between Sentence and Chunk Index Files | |
| 5.010 | _sentence_dependency_parse | Example of Mapping between Sentences and Indexed Syntactic Dependencies | |
| 3.306 | _sentence_lexeme | Example of Mapping Between Lexeme Indices and Sentences | |
| 2.004 | _table_caption | Example of Table Caption Index File | |
Directory contains 709.234 Bytes in 25 Files | |||
Total: 2.629.354.610 Bytes in 85 Files | |||

This page last edited on 16 October 2025.